导读 本文聚焦于在线营销场景下 Uplift(因果推理中的增量效应建模)效应设计。
此内容围绕着以下几点展开:
1. 背景与问题
2. 带约束的端到端 Uplift
3. 面向大规模上下文的 Uplift
4. Q&A
分享嘉宾|孙泽旭 中国人民大学高瓴人工智能学院 博士生
编辑整理|王震南
内容校对|李瑶
出品社区|DataFun
01
背景与问题
1. 在线营销的重要性
(1)在线营销场景
常见场景
短信推送场景:通过手机短信向用户发送优惠券或营销信息。
应用内弹窗/活动场景:在用户打开 APP 时,通过弹窗形式展示营销活动/推广内容。
问题建模
数据建模:对用户行为、偏好等数据进行分析建模,以确定推送策略及目标用户群体。
个性化推送执行:根据建模结果,向不同用户定向发送匹配其特征的短信、APP 弹窗等营销内容。
(2)人群激励矩阵
四类用户类型及其行为特征:
Persuadables:激励后购买,无激励不购买
Sure things:无论是否激励均购买
Lost causes:无论是否激励均不购买
Sleeping dogs:激励后不购买,无激励反而购买
目标人群:识别并干预 Persuadables 用户以实现转化
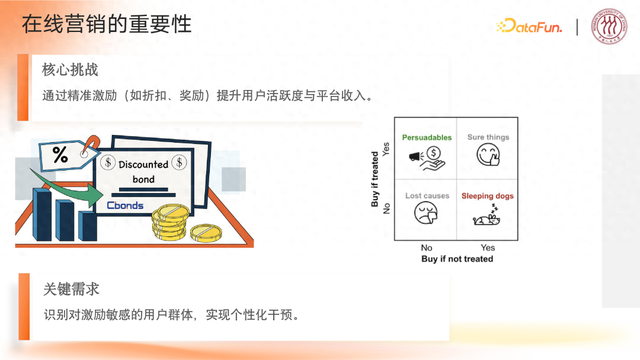
(3)核心挑战与需求
精准激励敏感用户(Persuadables 用户)以提升活跃度和平台收入。
识别激励敏感用户群体(如 Persuadables 用户),实现个性化干预,自动完成转化。
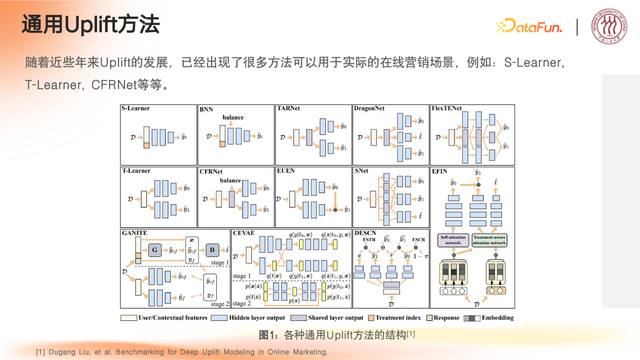
2. 现有研究与局限
(1)传统 Uplift 建模方法
发展脉络与趋势
早期阶段:以统计模型(S/T-Learner)和简单神经网络(TARNet)为主,侧重基础建模。
深度学习兴起:通过对抗训练(DragonNet)、多任务学习(EUEN)等提升性能。
前沿方向:结合 GAN(GANITE)、公平性(EFIN)、结构因果模型(DESCN)等解决复杂问题。
传统统计方法(早期传统方法)基于统计学或机器学习的经典方法,不涉及深度学习技术,通常通过两阶段或线性模型建模。
S-Learner
T-Learner
BNN(Bayesian Neural Network)
CEVAE(Counterfactual Estimation via Augmented Neural Networks)
深度学习基础方法(早期深度学习方法)首次将深度神经网络应用于 uplift 建模,但结构相对简单。
TARNet(Twins Adapted Reverse Networks)
CFRNet(Counterfactual Regression Network)
现代深度学习方法
通过优化网络结构或引入注意力机制、对抗训练等提升 uplift 估计的准确性。
DragonNet
FlexTENet
EUEN(Enhanced Uplift Estimation Network)
SNet
增强或复杂结构方法
通过 GAN、元学习等技术进一步优化,或结合其他任务(如公平性、鲁棒性)。
GANITE(Generative Adversarial Nets for Estimating Individual Treatment Effects)
EFIN(Enhanced Fairness-aware Uplift Network)
DESCN(Deep Structural Causal Network)
混合与贝叶斯方法(Hybrid/Bayesian Methods)
结合传统统计与深度学习,或侧重贝叶斯不确定性量化。
CEVAE
BNN
共同目标
从各种维度为用户群体和最终响应之间去建模。
在线营销场景中,实现最终 uplift 的效应预估
Uplift 的本质
本质上,Uplift(因果推理中的增量效应建模方法)是基于用户的特征和不同激励机制,去预估不同用户行为响应的一个方法。
(2)现有方法的不足
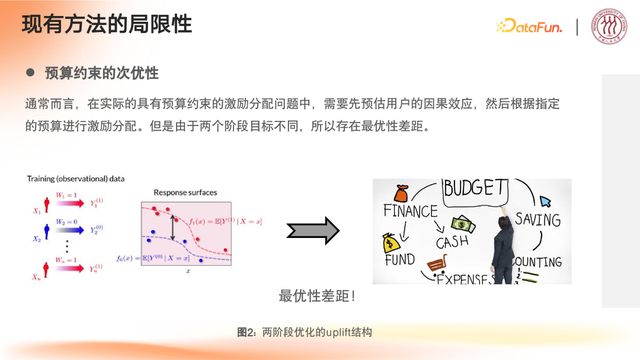
①两阶段建模最优性差距问题
两阶段原理
第一阶段:通过预估模型量化用户响应(uplift效应)的潜在价值
第二阶段:基于预算约束进行激励资源的最优分配
两阶段挑战
预算约束特性
在企业级资源分配场景中,预算限制具有显著刚性约束,尤其在涉及财务激励的场景下
分配逻辑局限性
传统方法依赖线性规划/整数规划等数学优化模型,需满足连续性或离散变量约束
因为采用两阶段决策架构,进行阶段分离预测时,一定会出现目标差距。
每个用户在平台中获得最后的激励分配数据和上一阶段的直接预测中间存在一定的差距,这就是目标上的预测差距。
②问题发生
传统方法在处理离散决策变量时可能存在的计算复杂度问题(如整数规划),或基于项目的分配策略导致的次优解风险。
两阶段建模导致目标差距
预估uplift效应与实际分配存在预测差距
分阶段联合建模导致次优解
预设方案
做一个端到端的分析,才能够消除这种最优性的差距。
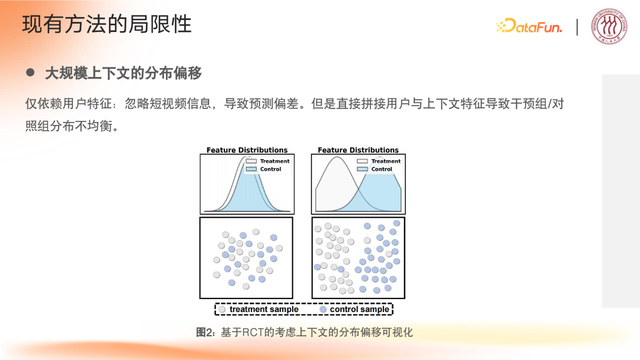
③大规模上下文的分布偏移
原理
仅依赖用户特征:忽略短视频信息,导致预测偏差,
直接拼接用户与上下文特征,导致干预组/对照组分布不均衡。
设计场景
针对短视频推荐系统的场景化建模优化问题:当前主流的推荐模型构建主要基于用户群体特征进行,但实际应用中存在显著的内容场景差异性。例如用户在浏览游戏类视频时,系统可能需要侧重推荐攻略解析或同类游戏内容;而当用户观看风景类视频时,则需转向旅游攻略或自然景观相关内容的推荐。这种因内容类型不同而产生的用户反馈与行为激励差异,导致单一用户群体模型难以精准匹配多场景下的推荐需求。
问题原因
未结合项目特征进行个性化干预。
部分方案采用基于项目的分配策略,忽视不同用户的效应差异。
02
带约束的端到端 Uplift
1. 问题定义
考虑预算的 uplift 实际场景:在带预算约束的 uplift 场景中,不仅要考虑收益(revenue uplift),即用户转化收益,同时要考虑用户成本(cost uplift)
Uplift 的第二阶段,往往规划成一个带约束的整数的分配问题。
在预算约束下的分配问题形式:
二值场景:分配与否的决策
多值场景:分配不同激励级别的优化
参考下图,在这个二值场景下是左边公式,在多值场景下是右边公式。

2. 方法设计
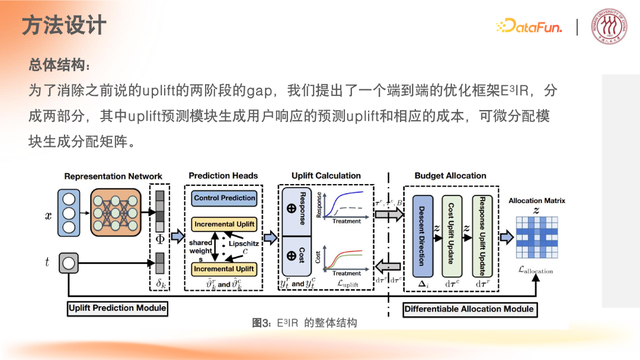
带约束的端到端的联合建模,是为了解决两阶段模块化设计导致的两阶段最优性差距问题。
端到端的优化框架 E3|R,依然分为两个模块
第一模块:uplift 预测用户对不同激励的响应计算(revenue uplift 和 cost uplift)
第二模块:基于预测 uplift 结果进行预算计算分配,传导进分配矩阵中,实现梯度计算的设计
创新点:梯度传导设计实现端到端优化
困难点:二阶段之间梯度求导数据的双向输出
3. 第一部分模块
(1)单调性约束
通过对单调性的约束建模,让它满足一个基本对应的效应。
①场景描述
在一个外卖优惠券发放的场景中,用户获得的优惠券金额与实际消费金额之间的关系需满足单调性约束。具体表现为:
正常逻辑:当优惠券金额增加时,用户的实际消费金额应随之增加或保持不变。例如:
获得 2 元优惠券时,用户消费 10 元;
获得 3 元优惠券时,用户消费 15 元;
获得 4 元优惠券时,用户消费应≥20 元(符合常规“满减”规则)。
违反约束的反例:若出现优惠券金额增加但消费金额反而减少的情况,则违反单调性约束。
例如:获得 4 元优惠券时,用户实际消费 12 元(低于 3 元券对应的 15 元消费)。
②约束核心
单调性约束要求优惠券力度与用户消费金额之间保持非递减关系,即更高的优惠券金额应对应更高的最低消费阈值(如“满 10 减 2”“满 15 减 3”等)。
若出现所述的“4 元券对应 12 元消费”的反例,则说明模型未满足该约束条件,需通过建模调整以确保消费金额随优惠力度递增。
③约束总结
激励力度与响应呈正相关,且激励预测值一定为正。

(2)平滑性约束
①场景描述
例如,若当前可用金额为 20 元,则选择花费 15 元(剩余 5 元)或类似小额消费是合理的;而若剩余金额为 20 元时,选择花费 100 元则因远超当前预算且违背常规消费认知被排除。该约束通过限制消费行为的突兀跳跃(如从 20 元直接跳到 100 元的不合理支出),确保消费金额与预算及场景合理性保持连续性和一致性。
②约束核心
在消费决策场景中,当预算为 20 元时,平滑性约束要求消费金额的变化需符合现实逻辑。
③约束总结
响应变化符合 Lipschitz 条件,避免突变,即保证整体预测的曲线上是平滑的。
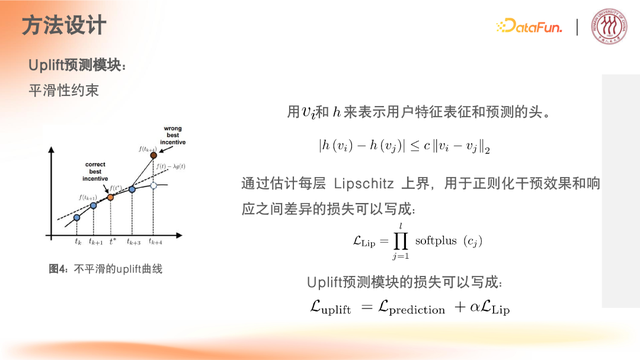
(3)第一部分约束总结
Uplift
预测模块损失可以写成:
4. 第二部分模块
(1)梯度传导方向的设计建模
response 函数的设计:response 函数在一个基础空间内,对应着一个可微函数。
建模的最终目的是为了解析 response 函数和预测损失值(Loss)互相之间的关系。
这个过程采用了整数规划的算法,通过针对 Z
函数
梯度传导方式进行求解。

(2)整数规划的局限
如果都是逼近某个整数点的值,按照整数规划,那么求解的能力就比较有限的。
为了实现梯度传导方向求解,针对 z 函数进行盈利和成本建模以及预算分配的向量计算处理,最终获得向量分解方向的结果,再通过向量分解的结果,分别进行成本以及预估成果等内容的更新,最终实现端到端的目标。

这个过程中,监督信号来源于用户行为数据。具体而言,系统通过采集用户在预估场景中受到的干预激励,构建监督信号。比如二值场景,T=0 或 1,来监督虚拟信号,以更新端到端的预测损失值方式。
最后,整体上就会得到我们预估的目标函数:

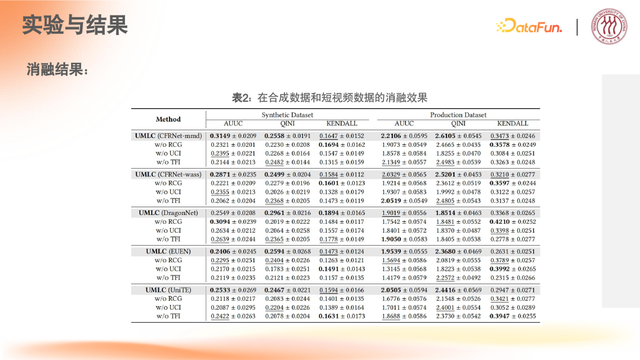
5. 实验与结果
(1)基于开源试集 Hillstrom 的算法数据测算
特定业务场景:针对不同的人在刷短视频时,给予不同的清晰度的范围,从整体上,实现在节省短视频 CDN 带宽的业务逻辑。
T=0-3,0-3 是针对不同的视频的一个清晰度提升标准;从 0 到 3,是视频清晰度从高到低的不同参数。

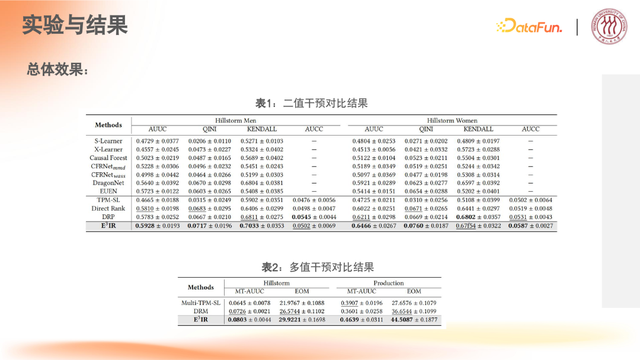
(2)论文实验展现的效果
S-Learner、X-Learner、Causal Forest、CFRNetmmd、CFRNet wass、DragonNet、EUEN 等方法,都是比较常用的二值干预的方法。
TPM-S、LDirect Rank、DRP 等方法也考虑到了分配场景的情况,但依然归属于两阶段建模的方式。
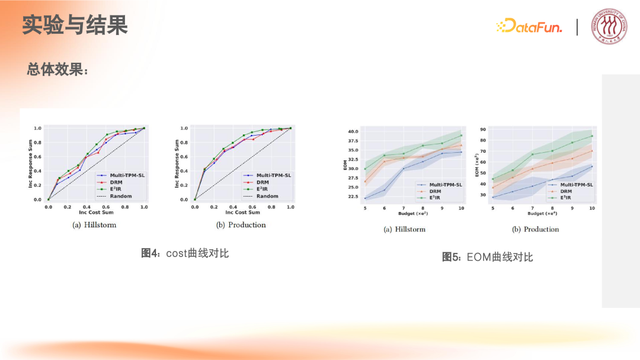
在多值干预的场景下,需要用 Multi-TPM-SL、DRM 等方法,做多阶段的分配。从本次实验的结果反映出,相较于两阶段/多阶段的方式,端到端的建模方式会对效果有较大提升。
(3)超参数分析以及预算(budget)分析
cost 曲线对比:超参数成本变化分析
EOM 曲线对比:预算(budget)的变化对实验结果预估的变化影响
6. 端到端解决方案总结
端到端的解决方案是一种基于预算约束的在线营销"预测+优化"的解决方案,该方案包含两个核心模块:
融合营销领域知识的提升预测模块,可生成单调平滑的用户响应曲线
采用整数线性规划(ILP),可微优化技术以减少两阶段方法的性能差距。
实际的问题中,很多场景需要端到端去做建模,以此获得效果上的提升。

03
面向大规模上下文的 Uplift 与问题
Uplift 预估是指,在特定场景中,将不同特征拼接形成整体数据的情况下,去实现因果效应建模的优化方法。
1. 案例定义
在线上开展 AB 实验的时候,仅可以控制用户的基本特征。
在短视频场景下,基于用户本身的特征,再结合视频特征,把两类特征通过上下文进行拼接,重构一个数据整体去计算特征。
场景约束:
特征空间构建时,可能会特别大。
会破坏 AB 实验的无偏分布效果。
场景问题:
在这种视频场景下,如何能够进行因果效应建模,是需要重点解决的问题。整体形式上,面向大规模上下文的 Uplift 和基本的 uplift 预估是基本一致的。因为在标准的 AB 实验的场景下,只考虑用户特征,X 参数在确定组跟控制组是一致的;在考虑到上下文特征的时候,产生的分布偏移如何消除,是这个方法中需要解决的主要的问题。

2. 方法设计
(1)总体结构
设计逻辑
首先,视频场景中特征维度极高,直接使用原始特征易导致计算负载过载。为此,需在用户特征融合的基础上,通过稀疏编码或注意力加权实现特征空间降维。
由于数据集直接拼接所有的用户特征,所以数据集的维度极高。比如短视频场景,一个用户看几个短视频,一个用户的特征就会被分散到几百个视频特征里,然后再复制一遍。
数据直接拼接,依然有很多视频特征仅在记录层面上,没有进行深度的数据洞察。即实际情况下,通过不同的平台收集的信息,在可记录的特征上没有特别明显的区分。
从这个角度出发,对用户的数据从更高维的引用空间,去做特征类别的区分,然后再进行空间的缩小。其次需要考虑如何把处理后的特征空间的特征和用户特征结合来考虑,做第二阶段的 uplift 的建模。
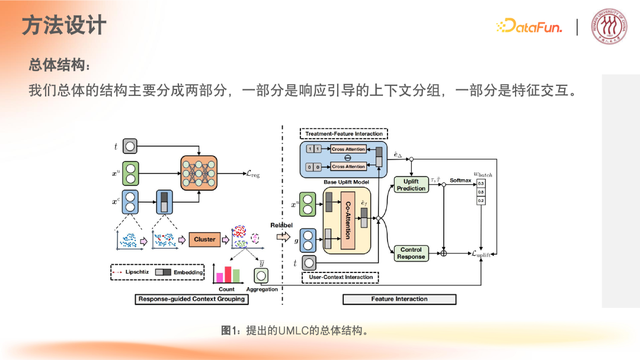
(2)第一部分:响应引导的上下文分组
处理特征:包括处理用户特征,处理项目 item(上下文特征),或者是短视频特征
聚类逻辑设计:首先最直接的方式是用户特征和 item 特征拼接,即上下文特征拼接,再设计回归逻辑,即结合 treatment 模块实现 response Y 的预估。这个阶段主要是靠 response 引导,即用用户的对应的 Y 标签,去做这部分特征的信号监督。
embedding 设计:针对上下文特征的 embedding 模型。embedding 模型满足一些基础的条件,即假设 1 和假设 2。
假设一:有一些上下文特征对这个用户的最终影响比较相似。
假设二:得到函数会满足某些性质,即所谓的这个 embedding 需要去满足某些性质。
完成以上步骤后,就可以开展相关的段落长本文向量的设计,以及聚类式的 embedding 维度设计。

预测损失(loss)函数部分的设计逻辑
模型架构
预测任务本质上是回归问题:通过融合上下文特征与新增的嵌入模型(需满足可微性、低秩性等基础性质),构建用户对视频的响应预测函数。
模型训练时,重点学习特征空间的低维表征,最终输出用户对不同视频的预测结果 Y。
样本平滑处理
实际场景中,需解决用户行为稀疏性问题:将不同用户的视频浏览行为统一为标准化特征,以提升预测稳定性。
现有方法采用简单聚合策略:对同一视频类别下的所有预测结果 Y 直接取平均值,作为该类别最终响应预估。

(3)第二部分:特征交互
特征交互设计思路
在设计 Attention 机制时,未采用传统理论框架,而是聚焦于如何更有效地整合特征、用户特征及上下文特征。通过构建特定的 Attention 结构,实现了用户特征与激励、上下文特征的交互,并进一步实现了用户特征与干预激励的融合。最终,这一过程完成了整体的 uplift 预估任务。

3. 实验与结果
基于两个数据集进行实验
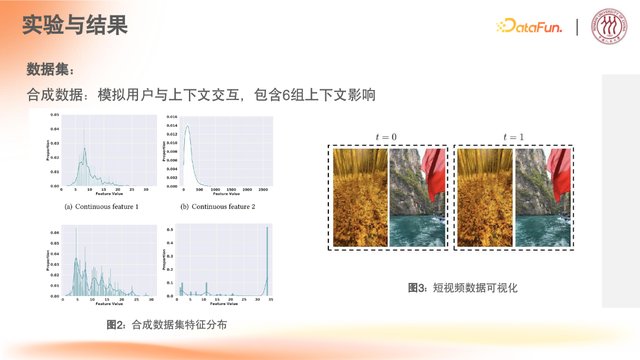
合成数据集
首先,构建一个标注有真实类别的合成数据集,用于验证设计思路的优越性。设计该数据集的原因在于,上下文特征存在类别差异,需排除干扰因素。
特定应用场景:清晰度建模的场景
案例:用户看游戏视频时,会需要高清的游戏视频;但是当用户看一些侧重内容的短视频,例如短剧、搞笑段子类内容时,用户的感受更聚焦在内容上,对视频的清晰度要求会比较低。
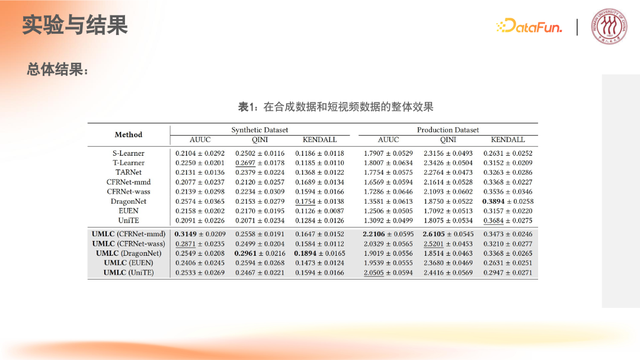
整体框架效果实验
整体框架实现逻辑是先对 Uplift 特征空间的上下文特征进行聚类设计,再实现特征交互,最后进行 Uplift 预估。这种设计可与众多现有方法结合,是一种自由建模方式。以下数据用于证明该方法的有效性。
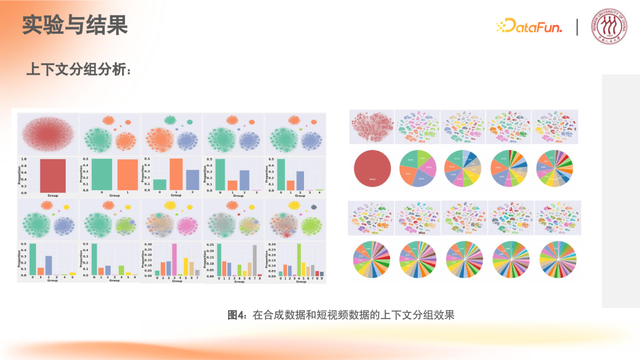
消融结果
可视化实验效果
合成数据效果
在基于一致性合成数据的实验中,对用户特征进行分组时,可以参考特征量来进行分组,这样就能取得更好的效果。从实验组的六组可视化效果中,能清晰看到它们在对应空间中的表征完全区分开来,基本和合成数据上的效果保持一致,因为合成数据原本就设计了六类特征。由此,再从这六类特征的角度出发,在隐空间内确实能够找到一个最优的分布表征形态。
实际数据效果
在实际的数据上也实现了聚类分组的效果。
4. 面向大规模上下文解决方案总结
响应引导的上下文分组:最主要部分就是设计上下文分组,这是在海量的 item 特征存在的情况下,实现用户特征跟商用特征的联合建模。
特征交互:融合用户-上下文和治疗-特征双重交互,主要为了更好地融合不同特征组到建模完成之后的特征效应,保障 uplift 预估的相对准确性。

04
Q&A
Q1:在E|R整体结构图里,与传统两阶段决策相比,新的学习框架整体计算复杂度增加多少?
第一阶段:预估因果效应,第二阶段:基于预估的因果效应进行整数规划预算分配。
A1: 该学习框架的计算复杂度主要体现在求解器实现梯度求导方向的部分,存在一定的复杂度,主要取决于最终的特征空间大小。计算过程涉及各个方向的向量分解。但在实际操作中,设计梯度方向时不会让整个空间过大,因为计算会不断在各个方向探索。相较于设计较大的特征更新策略,直接采用 Jax 库等通用特征设计、约束梯度传导方向以实现端到端约束更为有效。
Q2:在可导的分配模块当中,定义了一个匹配函数和不匹配函数,这个对应的分配预估损失值,对应具体的物理含义是什么?
A2:从物理含义来讲,我们是定义了解的标准,即 feasible,infeasible。推断的依据就是欧氏距离,一个基于几何理解定义的结果。在模型中,就是解的特征和 uplift 以及 budget 之间的欧氏距离。定义距离满足什么性质,就会对解的性质 feasible 和 infeasible 进行定义。
Q3:treatment 模块的多值场景适用于连续值吗?还是离散值?
A3:考虑的是离散多值,不是连续值。
Q4:生产应用时是直接从头进行端到端训练吗?
A4:是的。生产应用时,先直接把这个用户激励去作为标签,再把用户的 response 去做回归计算,最后进行端到端的训练。
以上就是本次分享的内容,谢谢大家。
大财配资-深圳配资开户-配资平台提供咨询-网上配资炒股网站提示:文章来自网络,不代表本站观点。